




Tijdens projecten en trainingen krijg ik wel eens een dataset toegespeeld van één van de deelnemers. Een spijtige observatie, die ik al te vaak maak, is dat de datastructuur en de datakwaliteit te wensen overlaat. Ik heb het hier niet over de inhoud van de aangeleverde tabellen, maar over hoe die tabellen er zelf uitzien. Deze simpele handvaten kunnen ervoor zorgen dat de data veel makkelijker bewerkbaar en bruikbaar zijn om hoge kwalitatieve data-analyses mogelijk te maken:
- Werk altijd met éénvoudige, volledig gevulde kolommen. Zeker als het over resultaat data, specificatie data, setting data en time stamp data gaat. Start in de eerste beschikbare cel in je spreadsheet. Specifieke dataverwerkingssoftware zal je daar trouwens vaak toe dwingen.
- Gebruik de eerste kolom altijd voor de time stamp. Wanneer is elk meetpunt genomen. En noteer ook wie het data punt heeft geregistreerd, met welke meetapparatuur en met welk protocol. Ik noem nu drie voor de hand liggende items, maar deze lijst kan behoorlijk lang worden. Wat er gemeten en genoteerd dient te worden, kan je voorbereiden aan de hand van een data collectieplan. Echter, ook een eenvoudige Ishikawa die de 6M’s in kaart brengt, kan je al een heel stuk op weg zetten.
- Hou de hoofdingen van kolommen eenvoudig, eenduidig, enkelvoudig en kort. Data voor specificaties, eenheden, etc… schrijf je beter weg in een extra kolom. Als je dit niet doet en je wil deze data later importeren in specifieke dataverwerkingssoftware dan loopt het door het overtreden van deze simpele regel al vaak fout.
- Vermijd alle toeters en bellen die in de huidige spreadsheets voorhanden zijn. Gebruik deze mogelijkheden zeker in rapporten en conclusies, maar niet in datatabellen. Ook hier struikelt dataverwerkingssoftware vaak over.
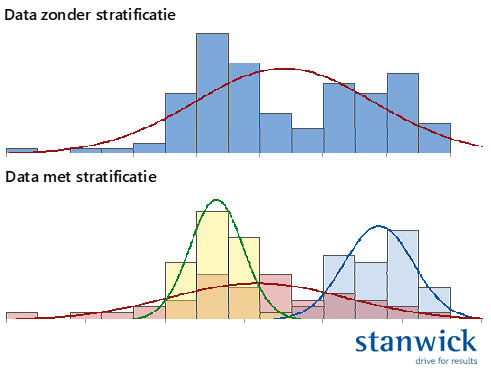
Naast een kwalitatieve tabel is uiteraard ook de inhoud belangrijk. Naast een voldoende grote steekproef zijn er nog twee belangrijke aandachtspunten: 1) Zorg dat de data representatief is voor wat je wil visualiseren en 2) Zorg dat je de context mee verzamelt. Zodoende zal het makkelijker zijn datastratificatie toe te passen en te zorgen voor duidelijk interpreteerbare grafieken.
De komende weken zal ik met regelmaat een vervolg op dit thema publiceren en me richten op de verschillende groepen of categorieën van grafieken. De meeste gebruikte grafieken kan je opdelen in vier groepen: 1) Grafieken die zelf categorieën binnen de data visualiseren, 2) Grafieken die de frequentie van voorkomen visualiseren, 3) Grafieken die tijdseffecten visualiseren en 4) Grafieken die een relatie tussen twee of meerdere parameters zichtbaar maken.
