




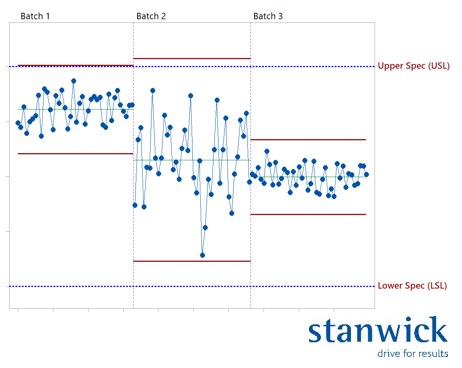
For this bit, I'll repeat the example from last time, where you see the results of 3 batches from the same process. With each batch, the average value shifts and certainly one batch has a significantly different variation from the other 2 batches.
A 'process capability index' is a single number that expresses the quality of a process compared to the given specification. As in the previous blogs, I will not use formulas here, but will try to explain as best I can what information you can get from this graph.
Below you can see the full analysis that includes 3 data boxes in addition to the graph, each of them of interest.
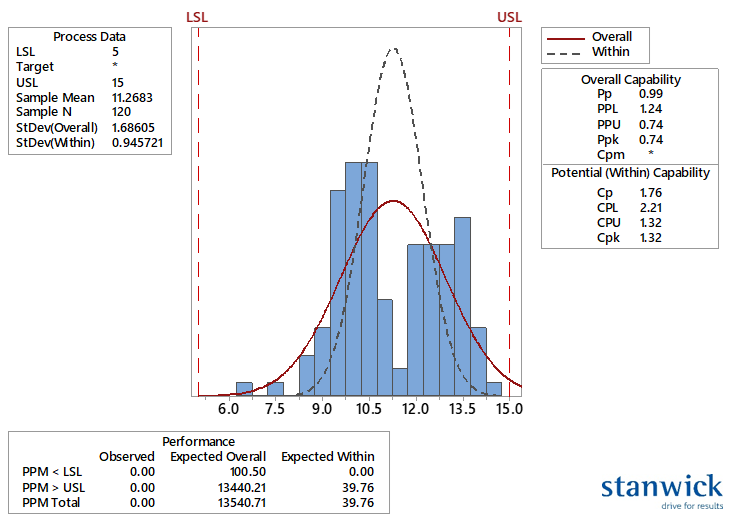
Data box 1 = Process Data
Here you can see an overview of the basic statistical data of the process. It is important to note that 2 different standard deviations are shown. The "Overall" standard deviation is the ordinary standard deviation calculated in the classical way. The "Within" standard deviation is the standard deviation calculated without including 'special cause' variation in the calculation. This provides a significantly lower value in this case. You can also see this in the graph. The red normal curve is the one with the "Overall" StDev, the black normal curve is the one with the "Within" StDev.
Data box 2 = Capability Indexes
- The overall (Pp) capability indexes are most frequently used in practice, although often under the wrong terminology. The Pp indexes are based on the overall (plain) StDev and thus show how the process is currently behaving against specifications. In day-to-day reporting of quality results, the Ppk index is the most important. The value depends on the situation and industry, but it is generally accepted that a value of 1.33 is the real minimum. By the way, the Pp value shows what the value of the Ppk would be should the average value be central between specifications.
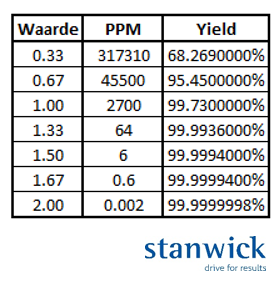
- The potential of within (Cp) capability indexes show the potential of this process if you can fully stabilise it and thus rid it of 'special cause' variation. Thus, the Cpk index shows the potential of the process. It is therefore mainly the comparison between Cpk and Ppk that can teach us something. If there is a big difference between the two, then there is a lot of 'special cause' variation in the process and then it is important to teach the organisation how to deal with this 'special cause' variation. Obviously, there is an important link with the 'Control Chart' and all kinds of 'root cause' analysis techniques, with the 'Is - Is not' method being my personal favourite. By the way, the Cp value shows the full potential of the process, i.e. the result when the average value is central to the specifications and when all 'special cause' variation has been removed from the process. If you want to optimise the values of these indexes even further, you need to address the common cause variation through the full Six Sigma toolbox.
Data box 3 = Performance in PPM (parts per million)
This table shows the expected number of off-spec products per million. The three categories speak for themselves.
Conclusion for this process: if I want to build a long-term relationship with this supplier, it will definitely have to do something about the variation between batches. Stabilising the average value will already have a big impact, but will not be enough. If I want to receive products with a Ppk of 1.5, the 'special and common cause' variation in the process will also have to be worked on.
I hope to show with this example that the Ppk - Cpk analysis is often a much more meaningful way of looking at quality than some paper exercises and also much easier to steer.
Just a little personal anecdote to conclude. About 10 years ago, I was working as a trainer at an automotive subcontractor. One of the participants showed me the results of such a Pp-Cp calculation from one of their suppliers. I saw very high values and 2 almost overlapping normal curves centrally between the 2 specifications. Yet the participant said, "We have almost half a per cent failure rate." I admit I was momentarily dumbfounded too, but soon the proverbial euro dropped. When asked how quality control was done at that supplier, the participant explained that the supplier used a sample of 25 from each box. After a little calculation, we discovered that the reported numbers were based on the average values of 25 pieces each time. Under the influence of the central limit theorem, the shrinking of the standard deviation due to working with mean values, the standard deviation in the graph was 5 times smaller than the actual one and thus the situation was presented much rosier than it was in reality.
Next time, we will discuss relationship plots, which help gain insights into relationships between process and output parameters.
